Outsmarted by LINQ-to-SQL
(and how to read a SQL execution plan)
I’m using LINQ-to-SQL on a current project, which is mostly a pretty positive experience (ignoring the odd frustrating limitation) – it’s incredibly easy to set up.
When using any object-relational mapper (ORM), LINQ-to-SQL, NHibernate or whatever, you can’t just blindly trust the SQL queries they’re generating. Hopefully, the queries will be as finely tuned as if you lovingly hand-crafted them yourself, but what if they’re not? Do you care if your production database server melts down? Sensibly, you’ll keep SQL Profiler open and scrutinise each new type of query.
Shock and horror
Following that advice, when I started with LINQ-to-SQL I used SQL Profiler to see what it was getting up to. For example, I had everyone’s favourite Customer-Orders relationship:
… and I was doing a query to find the customers who have never ordered anything:
ExampleDBDataContext context = new ExampleDBDataContext(); // The query var customers = from c in context.Customers where c.Orders.FirstOrDefault() == null select c; foreach (Customer c in customers) Console.WriteLine(c.Name);
It worked, but I was appalled to see it generate the following SQL:
SELECT [t0].[CustomerID], [t0].[Name], [t0].[CreatedDate] FROM [dbo].[Customers] AS [t0] WHERE NOT (EXISTS( SELECT TOP (1) NULL AS [EMPTY] FROM [dbo].[Orders] AS [t1] WHERE [t1].[CustomerID] = [t0].[CustomerID] ))
Smell that dirty subselect! As someone who’s been brought up on the mantra “subselects are bad; always use joins!”, I wanted to write to Microsoft and educate them that the correct SQL would be:
SELECT [t0].[CustomerID], [t0].[Name], [t0].[CreatedDate] FROM [dbo].[Customers] AS [t0] LEFT OUTER JOIN [Orders] o ON t0.[CustomerID] = o.[CustomerID] WHERE o.[OrderID] IS NULL
Mmm, that’s much cleaner and nicer. Lovely elegant joins. Stupid LINQ-to-SQL…
I think you can guess what’s coming
Let’s put my beliefs to the test. When there are 100 customers and 1000 orders, the two methods’ execution plans look like this:
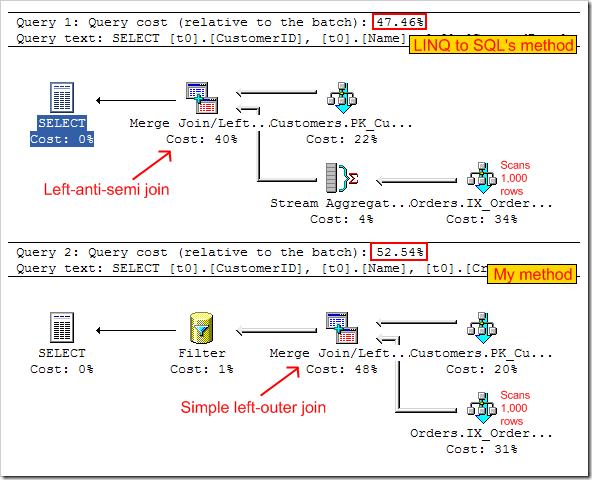
Notice the “query cost” values (smaller is better).
LINQ-to-SQL’s method does a “stream aggregation” to get a list of distinct CustomerIDs from the Order table, then left-anti-semi join excludes any Customer rows which match one of those IDs. My “left outer join” method, on the other hand, joins all Customer-Order pairs, then has a filter to exclude any joined rows that have a CustomerID.
LINQ-to-SQL’s method wins slightly, but only very slightly. The near-identical performance is not surprising since they both scan all 100 customers and all 1,000 orders.
More data, more data
Repeating the experiment, but now with 100 customers and 1,000,000 orders, the execution plans change to:
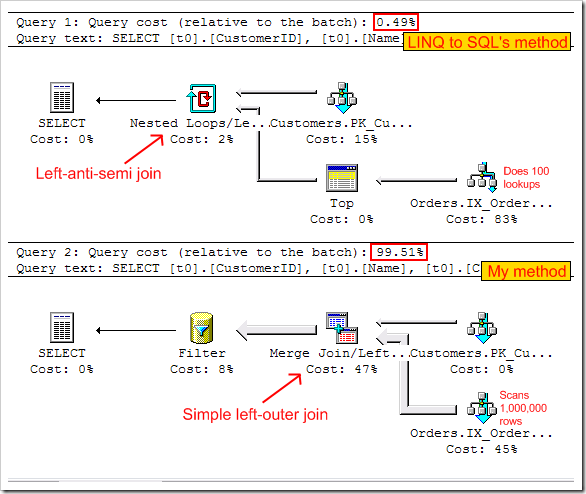
Agh! My elegant method is about 200 times slower than LINQ-to-SQL’s clumsy subselect! But why?
The query plan for my method remains identical, so now it has to scan all 1,000,000 order rows, joining them to customer records, and filtering out any customers with orders.
The query plan for LINQ-to-SQL’s method has changed, so now for every Customer record, it just subselects the TOP 1 matching Order record and does a left-anti-semi join (so Customers are included only if no matching Order was found). This means it doesn’t have to look through all 1,000,000 rows – it can bail out as soon as the first matching Order is found. Assuming you have a CustomerID index on the Order table, this is very fast indeed.
Conclusions
Obviously, the conclusion isn’t “LINQ to SQL is always right”, or “subselects are always better than JOINs”. I am merely admitting that LINQ to SQL isn’t as dumb as I thought, nor am I as clever as I thought. Oh, and scrutinising LINQ to SQL using SQL Profiler isn’t always enough; you sometimes need to inspect those execution plans too.